Punti di vista
Navigare in una marea di dati
Cosa sono i dati?
Quando si parla di Digital Twin, i dati sono fondamentali. Le potenzialità di questo tipo di sistema sono caratterizzate dal fatto che il modello digitale e il modello fisico producono una quantità enorme di dati.
Prima di tutto, cerchiamo di definire cosa significhi “dato”. La Treccani definisce il dato come: “Ciò che è immediatamente presente alla conoscenza, prima di ogni forma di elaborazione”. Questo significa che il dato, nel nostro caso, è tutto ciò che viene generato dalla parte fisica e dalla parte digitale, senza alcuna elaborazione.
Quando uno o più dati vengono elaborati, si parla di “informazione”. Infatti, l’informazione è il risultato dell’elaborazione e dell’aggregazione di uno o più dati.
Nel Digital Twin, basato sul BIM, esistono diverse categorie di dati che abbiamo classificato in questo modo:
- Dati di progettazione:
Sono dati statici nel tempo, raccolti durante la fase di progettazione e costruzione dell’edificio. Si tratta di costanti che cambiano raramente; eventuali modifiche a questi dati comportano costi molto elevati, poiché richiederebbero interventi anche sull’ambiente fisico. - Dati generati dal IoT:
Sono dati dinamici, in cui la variabile tempo è fondamentale. Un dato non raccolto in un determinato istante è perso per sempre. Questi dati vengono generati continuamente e sono creati automaticamente da sistemi informatici. - Dati generati dall’utente:
Le persone sono al centro di questa categoria di dati. In questo caso, i dati possono essere ricostruiti affidandosi alla memoria dell’utente, ma tale ricostruzione potrebbe essere imprecisa a causa di diversi fattori. Questo evidenzia la necessità di un sistema di recupero dati rapido, che permetta l’accesso immediato nel momento in cui è necessario inserire il dato. Ad esempio, se occorre raccogliere dati in cantiere, non è efficace utilizzare applicativi che funzionano solo da computer, dato che quest’ultimo potrebbe non essere disponibile in alcuni contesti. - Dati generati dalle simulazioni:
Questi dati possono essere replicati e generati ogni volta che lo si desidera. Tuttavia, la complessità risiede nella creazione di un modello matematico che produca dati realistici. Inoltre, è difficile definire con precisione gli elementi di input necessari per generare tali dati.
Da queste categorie di dati è possibile generare molte informazioni, entrando così nel mondo dei Big Data e dell’intelligenza artificiale. Si parla di Big Data perché i dati provenienti dal sistema sono molto variegati, complessi, non standardizzati e spesso in quantità enormi.
Per ricavare informazioni utili alla gestione e ai processi, potrebbe essere utile fare uso dell’intelligenza artificiale (AI), che permette di gestire questa grande mole di dati e di estrarne informazioni significative.

Big data
I big data indicano genericamente una raccolta di dati informatici così estesa in termini di volume, velocità e varietà da richiedere tecnologie e metodi analitici specifici per l'estrazione di valore o conoscenza. Il termine è utilizzato dunque in riferimento alla capacità (propria della scienza dei dati) di analizzare ovvero estrapolare e mettere in relazione un'enorme mole di dati eterogenei, strutturati e non strutturati (grazie a sofisticati metodi statistici e informatici di elaborazione), al fine di scoprire i legami tra fenomeni diversi (ad esempio correlazioni) e prevedere quelli futuri. I big data possono essere utilizzati per diversi scopi tra cui quello di misurare le prestazioni di un'organizzazione nonché di un processo aziendale.
Intelligenza atificiale
La norma ISO/IEC 42001:2023 Information technology - Artificial intelligence Management System (AIMS) definisce l'intelligenza artificiale come la capacità di un sistema di mostrare capacità umane quali il ragionamento, l'apprendimento, la pianificazione e la creatività.
Le difficoltà nella raccolta dati
La raccolta di questi dati può presentare diverse difficoltà, tra cui:
- Decidere quali dati sono necessari e quali sono inutili:
È importante ricordare che la tecnologia si evolve, e un dato che oggi sembra inutile potrebbe rivelarsi prezioso in futuro. Questo dilemma richiede un’analisi approfondita per stabilire quali dati conservare e a quali rinunciare. - Automatizzare la raccolta dei dati:
Raccogliere dati in modo automatizzato è fondamentale per evitare perdite causate da dimenticanze o distrazioni. - Certificare la veridicità dei dati:
È necessario verificare se un dato è reale o se è il risultato di un errore tecnico. - Impossibilità di raccogliere alcuni dati:
Alcuni dati potrebbero non essere raccolti a causa di limiti tecnologici o di costi troppo elevati necessari per il loro recupero. - Pulizia dei dati:
I dati raccolti potrebbero essere contaminati da processi di elaborazione intermedi, contenendo così informazioni aggiuntive che generano confusione durante l’analisi successiva. - Archiviazione di grandi quantità di dati:
La generazione di grandi quantità di dati richiede anche molto spazio per la loro archiviazione. Per questo motivo, è necessario valutare se sia utile sintetizzare i dati, accettando il rischio di perdere alcune informazioni, al fine di facilitare l’accumulo di nuovi dati nel tempo.
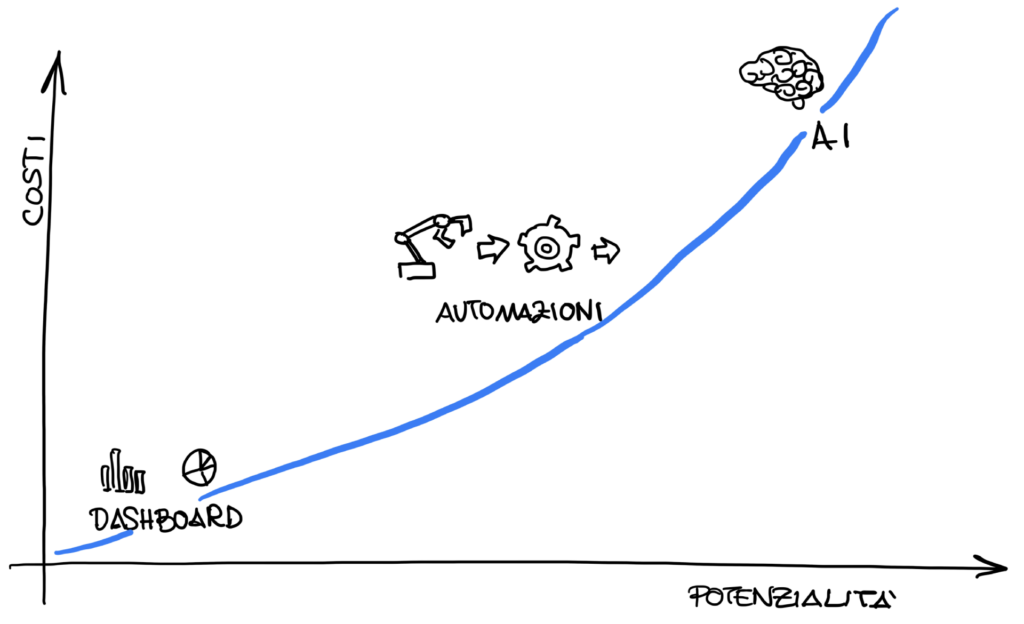
I livelli di gestione del dato
Per gestire questa grande mole di dati, esistono diversi sistemi, dai più tradizionali ai più complessi. I dati possono essere analizzati tramite dashboard, generando grafici utili a identificare andamenti o problematiche, evidenziando eventuali picchi.
In alcuni casi, è possibile implementare automazioni che generano errori o azioni in base a specifici valori sentinella. Ad esempio, nel nostro software Symmetry, è possibile evidenziare elementi nel modello 3D in relazione all’elaborazione di determinati dati.
Si può arrivare, infine, all’utilizzo dell’intelligenza artificiale per generare azioni automatiche basate su modelli matematici che analizzano e prendono decisioni al posto nostro.
Naturalmente, tutte queste elaborazioni comportano costi e potenzialità crescenti.